Ha van az emberi életnek olyan területe, ahol mindenképpen hatalmas hasznot remélhetünk a mesterséges intelligenciától, akkor az biztosan az egészségügy. Már jelenleg is több helyen AI rendszerek segítik a CT, MRI, mammográfia és röntgen képek értékelését, például tüdőcsomók, agyvérzésre utaló jelek vagy daganatok korai felismerésében. De a patológiai képelemzésben vagy a klinikai dokumentáció elkészítésében is használnak mesterséges intelligenciát.
A jövőben viszont pár éven belül könnyedén megtörténhet, hogy az AI fog segíteni diagnózisokat felállítani. Alapvetően úgy kell elképzelni egy ilyen rendszert, hogy az AI végighallgatja a tünetekkel kapcsolatos beszélgetést az orvossal, elemzi a kapott teszteredményeket, majd javaslatot tesz a következő lépésekre. Egy új tanulmányban a kutatók kimutatták, hogy a nagy nyelvi modellek a bonyolult és potenciálisan életveszélyes állapotok diagnosztizálásában gyakran felülmúlták az orvosokat, méghozzá a valódi sürgősségi ellátás korai, gyors és információhiányos szakaszaiban is, amint arról a Science folyóirat beszámolt.
A sürgősségi ellátás korai szakaszában a modell az esetek körülbelül 67%-ában azonosította a helyes vagy ahhoz nagyon közeli diagnózist, szemben az orvosok 50–55%-ával. A publikált tanulmányban az OpenAI o1 modelljét tesztelték öt feladatban. Mindegyiknél a modellnek kézzel kiválasztott orvosi profilokat kellett átolvasnia, majd diagnózist javasolnia, következő lépéseket meghatároznia, vagy megbecsülnie egy adott jövőbeli egészségügyi változás valószínűségét. Mind az öt feladatban az o1 hasonlóan vagy jobban teljesített az orvosoknál. Az egyik feladatban az o1 a megvizsgált esetek 98%-ában tökéletes klinikai érvelési pontszámot kapott, míg az osztályos orvosok ezt az esetek mindössze 35%-ában tudták elérni.
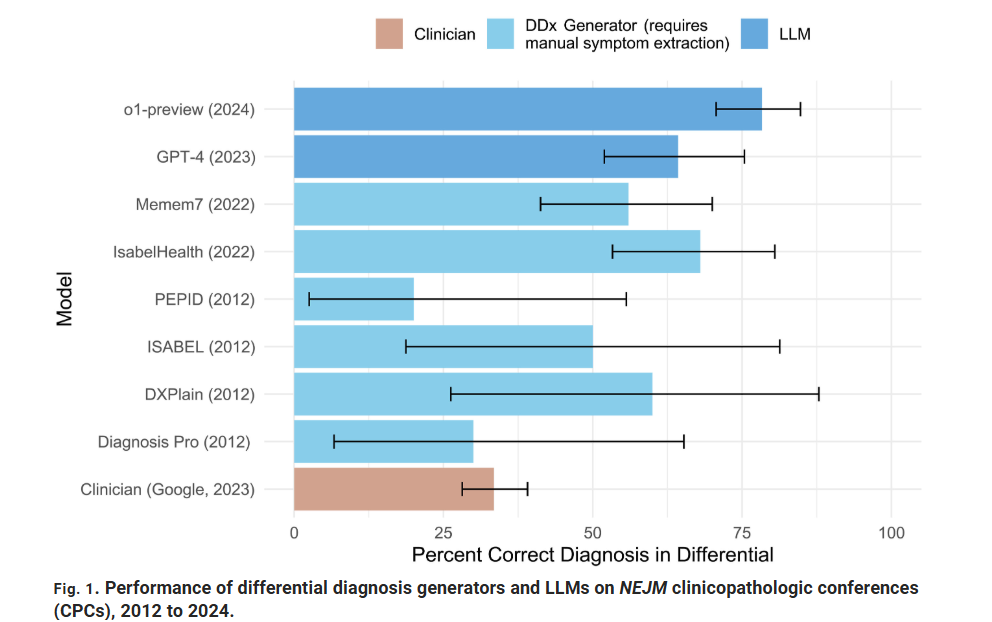
Az egyik legkritikusabb LLM tesztben az ellátás három pontján vizsgálta meg az AI a sürgősségi osztályra érkező betegeket. Amikor egy beteg megérkezik a sürgősségire, először triázs szerint egy nővér besorolja állapotának kritikusságát, majd egy orvos megvizsgálja, végül a kezelőorvosnak meg kell határoznia a megfelelő teendőket. Minden egyes lépésben fennáll a tévedés lehetősége, hiszen a betegek sokszor nehezen tudják elmondani tüneteiket, az orvosok pedig egyszerre több stresszes esettel is foglalkozhatnak. A korai triázsdöntések különösen nehezek, mert az orvosoknak gyorsan kell cselekedniük, és a hibáknak azonnali következményei lehetnek. Egy orvos, aki például összetéveszt egy vérfertőzést a közönséges náthával, antibiotikum nélkül hazaküldheti a beteget – ami potenciálisan halálos döntés.
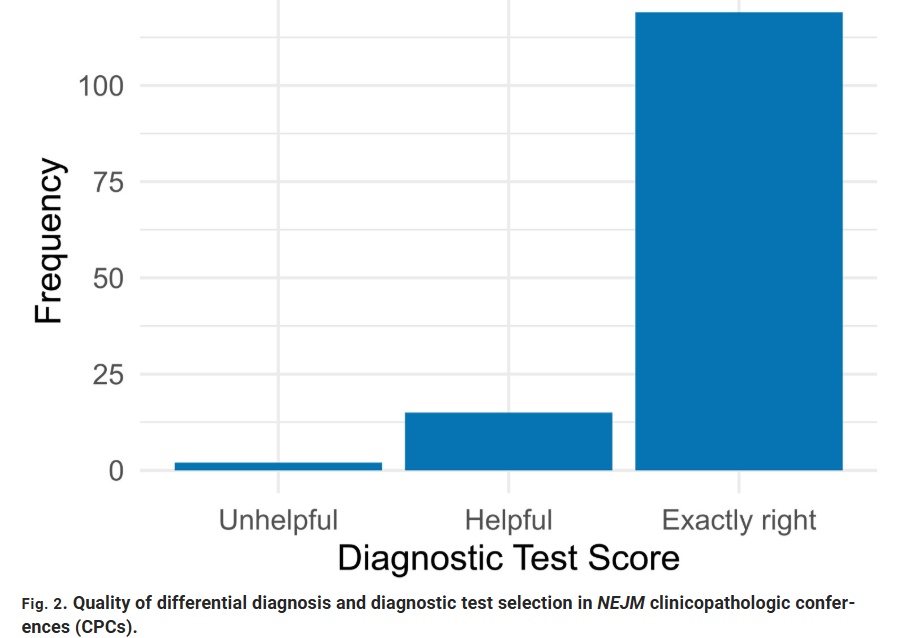
Ezért volt ez egy fontos pontja a tesztnek az LLM számára, mert itt hiányos és torz adatokkal kellett az adatvédelmi aggályokkal is szembesülő OpenAI modellnek dolgoznia. A sürgősségi ellátás korai szakaszában, amikor a beteg bejelentkezik és korlátozott tájékoztatást ad a panaszairól, az o1 az esetek 67%-ában azonosította a pontos vagy ahhoz közeli diagnózist – több mint 10%-kal magasabb arányban, mint két, ugyanolyan eseteket kapó orvos. Bár a különbség kissé csökkent, amikor több adat állt rendelkezésre, az LLM az ellátási folyamat későbbi szakaszaiban is 2–10%-kal felülmúlta az orvosokat.
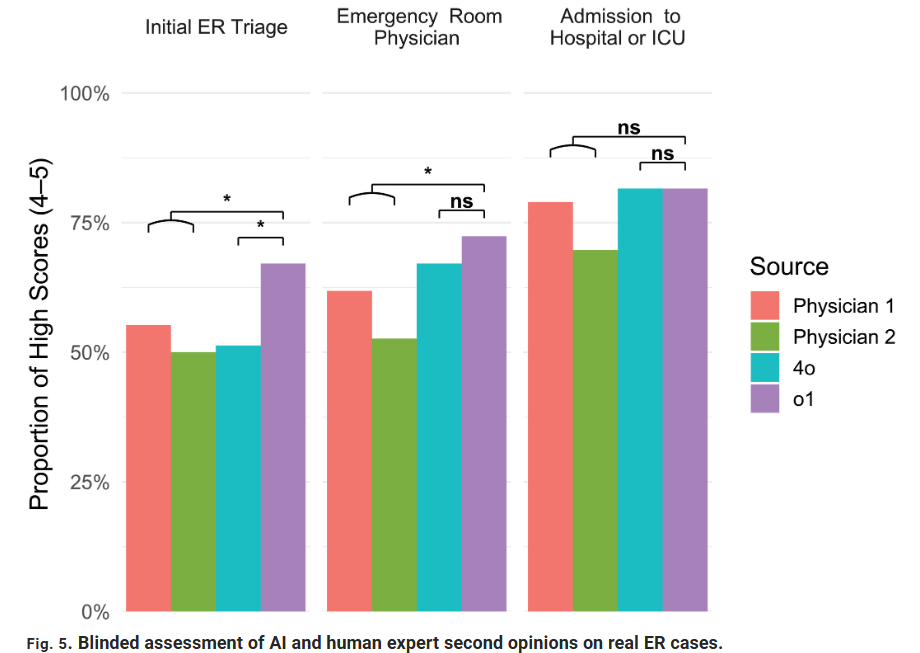
Fontos kiemelni azonban, hogy ez a sürgősségi ellátásra vonatkozó teszt volt és nem kerültek vizsgálatra nagyon hosszú betegkórtörténetek, ahol nem csak pár szavas információk állnak rendelkezésre, hanem akár hónapok adatai. Emellett a tanulmány az o1-et kizárólag írásos esetinformációkkal látta el, és nem tartalmazott nem szöveges bemeneteket, például képalkotást, amelyek sok valódi diagnózis – köztük vérrögök és daganatok – esetén alapvető fontosságúak. Ezek a típusú tesztek elvileg a kutatócsapat következő kísérletének a fókuszpontjába kerülnek majd. Mert a végső cél az, hogy megértsék, ténylegesen képesek-e javítani a valódi betegállást az AI-rendszerek a kontrollált tesztek keretein kívül is.
Megjelent a BitcoinBázis oldalon.

